Faculty Research Profile

Youngsoo Jang


학력
- Mar. 2018 - Aug. 2022: Ph.D. School of Computing, KAIST, Advisor: Prof. Kee-Eung Kim
- Mar. 2016 - Feb. 2018: M.S. School of Computing, KAIST, Advisor: Prof. Kee-Eung Kim
- Mar. 2011 - Feb. 2016: B.S. Mathematical Science and School of Computing (Double Major), KAIST
주요 경력
- Sep. 2025 - Present: Assistant Professor, AIGS & Dept. of CSE, UNIST
- Aug. 2022 - Aug. 2025: Research Scientist (Squad Leader), LG AI Research
수상/학회/외부활동
- Top 5 Selection, Sovereign AI Foundation Model Project organized by the Ministry of Science and ICT (MSIT), as part of LG AI Research, 2025
- Qualcomm-KAIST Innovation Awards, Qualcomm, 2019
- 1st place on 8th Dialog System Technology Challenge (DSTC8) Multi-domain Task Completion Track, 2019
- Naver Ph.D. Fellowship, NAVER, 2018
- 3rd place on 5th Dialog State Tracking Challenge (DSTC5), 2016
지능 최적화 및 강화학습 연구실
AI Cognition Optimization & Reinforcement Learning Lab
지능 최적화 및 강화학습 연구실 (AI-CORE Lab) 은 강화학습을 통한 차세대 지능형 시스템의 이론적 기반과 실용적 응용을 탐구합니다. 본 연구실에서는 강화학습을 통해 AI Agent가 스스로 지능을 최적화하며 새로운 환경에서도 적응할 수 있는 알고리즘 개발을 목표로 하며, 특히 대규모 언어모델이나, 로봇, 그리고 산업 현장에서의 실제 문제 해결에 적용할 수 있는 강화학습에 대한 연구를 진행하고 있습니다. 이러한 연구를 통해 설명 가능하고 신뢰할 수 있으며, 실생활 및 산업 현장에도 도움이 되는 차세대 인공지능을 만들어 가는 것을 목표로 합니다.
The AI Cognition Optimization with Reinforcement & Exploration (AI-CORE) Lab explores both the theoretical foundations and practical applications of next-generation intelligent systems through reinforcement learning. Our goal is to develop algorithms that enable AI agents to optimize their own intelligence and adapt to new environments using reinforcement learning. In particular, we conduct research on reinforcement learning that can be applied to large language models, robotics, and real-world industrial problems. Through this research, AI-CORE Lab aims to create next-generation AI that is explainable, trustworthy, and beneficial for both everyday life and industrial applications.
The AI Cognition Optimization with Reinforcement & Exploration (AI-CORE) Lab explores both the theoretical foundations and practical applications of next-generation intelligent systems through reinforcement learning. Our goal is to develop algorithms that enable AI agents to optimize their own intelligence and adapt to new environments using reinforcement learning. In particular, we conduct research on reinforcement learning that can be applied to large language models, robotics, and real-world industrial problems. Through this research, AI-CORE Lab aims to create next-generation AI that is explainable, trustworthy, and beneficial for both everyday life and industrial applications.
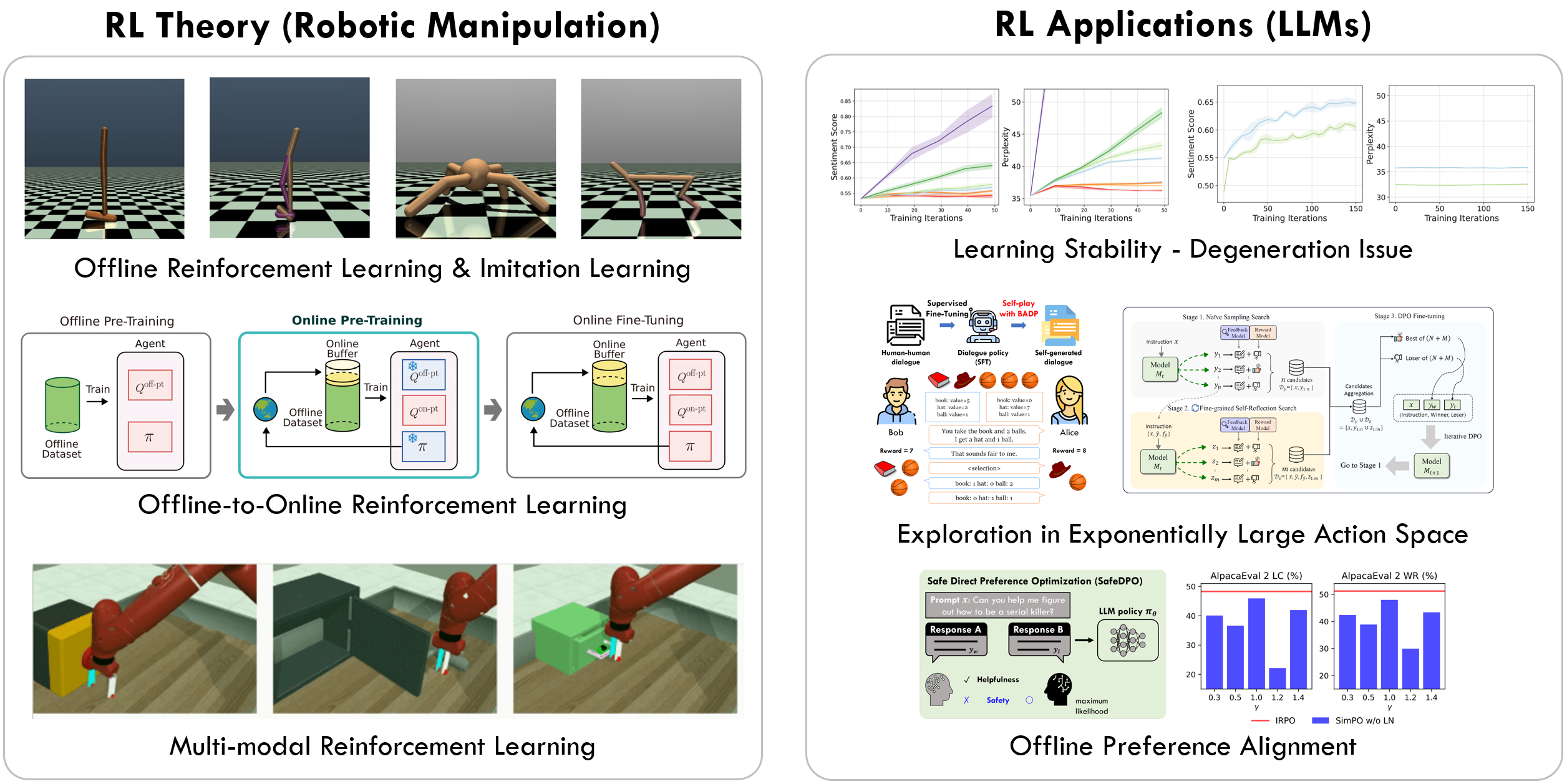
연구분야
강화학습, 대규모 언어모델, 대규모 언어모델 에이전트, 산업 인공지능 / Reinforcement Learning, Large Language Models (LLMs), LLM Agent, Industrial AI
Reinforcement Learning, Large Language Models (LLMs), LLM Agent, Industrial AI
연구 희망분야
인공지능 초지능, 로보틱스, 비전-언어-액션 모델, 산업 인공지능 / Artificial Superintelligence, Robotics, Vision-Language-Action (VLA) Model, Industrial AI
Artificial Superintelligence, Robotics, Vision-Language-Action (VLA) Model, Industrial AI
연구주제
- Reinforcement Learning for Large Language Models
- Large Language Models & LLM Agent
- Offline Reinforcement Learning & Offline-to-Online Reinforcement Learning
- Safe Reinforcement Learning
- Reinforcement Learning for Industrial AI
- Reinforcement Learning for Large Language Models
- Large Language Models & LLM Agent
- Offline Reinforcement Learning & Offline-to-Online Reinforcement Learning
- Safe Reinforcement Learning
- Reinforcement Learning for Industrial AI
국가연구개발사업 기술 분류체계
국가과학기술표준분류
EE. 정보/통신 > EE01. 정보이론 > EE0108. 인공지능
논문
- “Degeneration-free Policy Optimization: RL Fine-Tuning for Language Models without Degeneration”, Youngsoo Jang, Geon-Hyeong Kim, Byoungjip Kim, Yu Jin Kim, Honglak Lee, and Moontae Lee, Proceedings of International Conference on Machine Learning (ICML). 2024
- “SafeDICE: Offline Safe Imitation Learning with Non-Preferred Demonstrations”, Youngsoo Jang, Geon-Hyeong Kim, Jongmin Lee, Sungryull Sohn, Byoungjip Kim, Honglak Lee, and Moontae Lee, Proceedings of Neural Information Processing Systems (NeurIPS). 2023
- “GPT-Critic: Offline Reinforcement Learning for End-to-End Task-Oriented Dialogue Systems”, Youngsoo Jang, Jongmin Lee, and Kee-Eung Kim, International Conference on Learning Representations (ICLR). 2022
- “Monte-Carlo Planning and Learning with Language Action Value Estimates“, Youngsoo Jang, Seokin Seo, Jongmin Lee, and Kee-Eung Kim, International Conference on Learning Representations (ICLR). 2021